I haven't had time to examine this new research in great detail but it looks pretty good to me (maybe one or two minor caveats). They have fitted a fairly simple mechanistic statistical model to time series data for deaths in a large number of European countries, using a Bayesian hierarchical modelling approach to estimate the effects of various "non-pharmaceutical interventions" like shutting schools and banning large meetings which have been widely adopted. I suspect (could be wrong tho) that the reason for using a primarily statistical model is that it's quicker and easier for their method than a fully dynamical model like the one I'm using. They say it is fundamentally similar to SIR though, so I don't think their results should be any the worse for it (though perhaps the E box makes a difference?).
First and foremost, by far the most significant result IMO is that they find the initial R0 to be much larger than in the complex mechanistic modelling of Ferguson et al. This confirms what I suggested a few days ago, which was based on the fact that their value of R0 = 2.4 (ish) was simply not compatible with the rapid exponential growth rate in the UK and just about everywhere else in the western world.
Here are pics of their values for a number of countries, for their preferred reproductive time scale of 6.5 days. Left is prior to interventions, right is current post-intervention estimates.


You may spot that all the values on the right imply a substantial probability of R0 > 1, as I also suggested in my recent post. If the initial R0 is high, it's hard to reduce it enough to get it below 1. If true, that would mean ongoing growth of the epidemic, albeit at a lower rate and with a longer lower peak than would be the case without the interventions. I will show over the next few days what the implications of this could be over the longer term.
It's also important to realise that these values on the right depend on the data for all countries - this is the "hierarchical" bit - there is no evidence from the UK data itself of any significant drop in R, as you can work out from the below plot which gives the fit and a one-week forecast. There simply hasn't been long enough since the restrictions were put in place, for anything to feed through into the deaths. Though if it bends in the near future, that will be a strong indication that something is going on. They appear to be 3 days behind reality here - it looks like they haven't got the two small drops and most recent large rise.

Despite my best intentions, I don't really see much to criticise, except that they should have done this a week or two ago before releasing the complex modelling results in which they made such poor parameter choices. Obviously, they would not have been able to estimate the effect of interventions using this method, but they'd have got the initial growth rate right.
It's a little like presenting forecasts from one of the new CMIP6 models, without checking that it has roughly the right warming rate over the last few decades. You'd be better off using an energy balance that was fitted to recent history, especially if you were primarily interested in the broad details such as large-scale temperature trend. In fact that's a pretty direct analogy, except that the epidemic model is much simpler and more easily tuned than a state of the art climate model. Though they also had a bit less time to do it all :-)
As for the caveats however - I had to laugh at this, especially the description above:
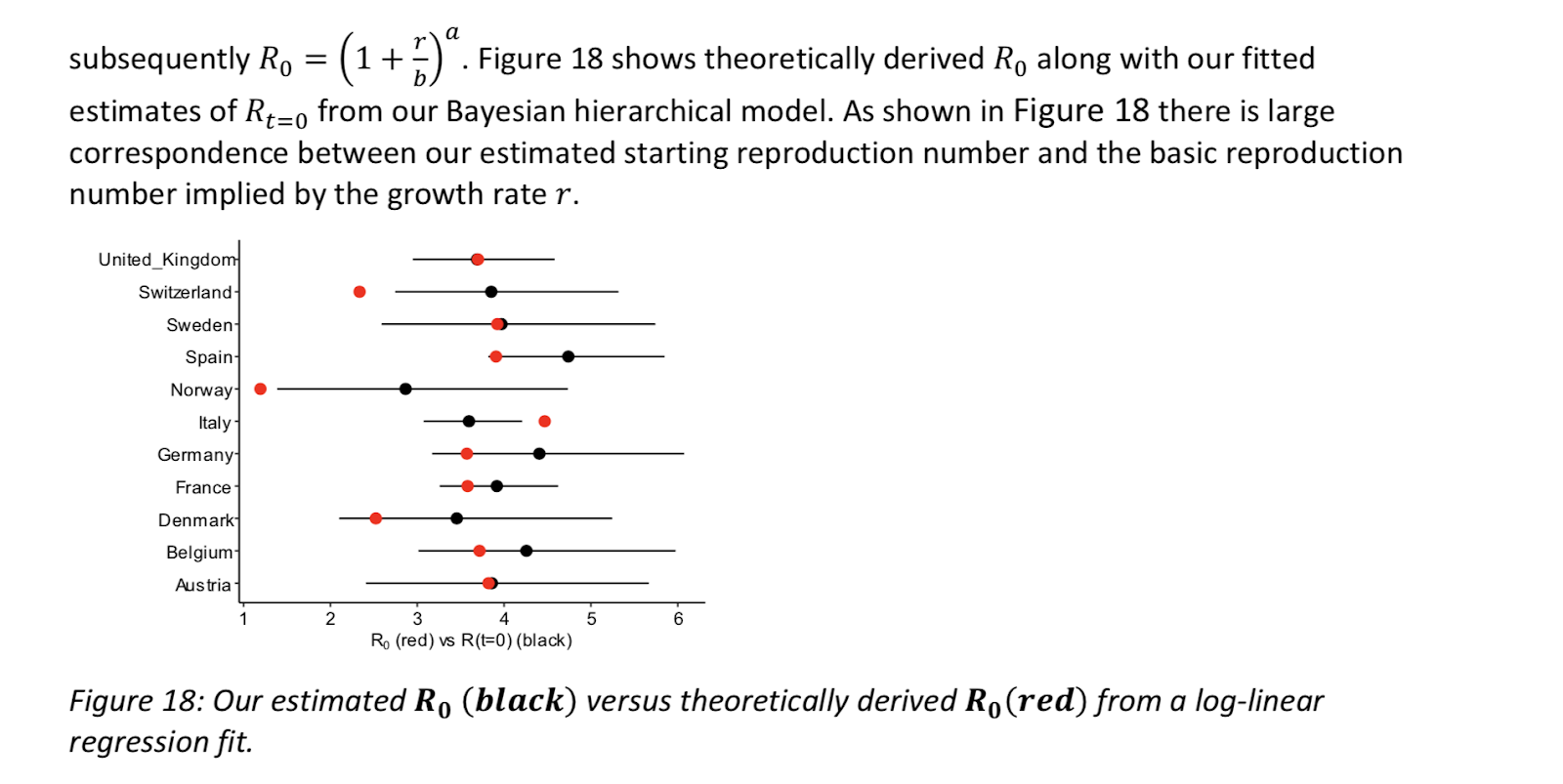
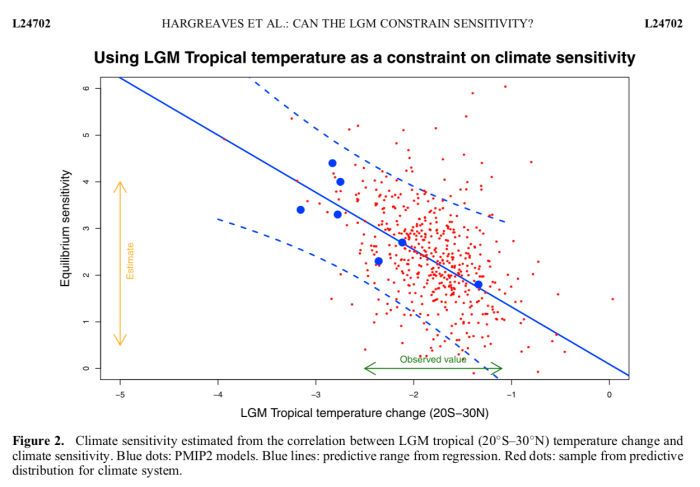
I remember seeing a similarly impressive "large correspondence" plotted in a climate science paper a while back. I pressed the authors for the correlation between the two sets of data, and they admitted there wasn't one.
But that's a minor quibble. It's a really interesting piece of work.
I am now just about in a position to show results from my attempts at doing proper MCMC fits to time series data with the SEIR model so it will be interesting to see how the results compare. This can also give longer-term forecasts (under various scenario assumptions of course).