The 2 and now 3-segment piecewise constant approach seems to have worked fairly well but is a bit limited. I’m not really convinced that keeping R fixed for such long period and then allowing a sudden jump is really entirely justifiable, especially now we are talking about a more subtle and piecemeal relaxing of controls.
Ideally I’d like to use a continuous time series of R (eg one value per day), but that would be technically challenging with a naive approach involving a whole lot of parameters to fit. Approaches like epi-estim manage to generate an answer of sorts but that approach is based on a windowed local fit to case numbers, and I don’t trust the case data to be reliable. Also, this approach seems pretty bad when there is a sudden change as at lockdown, with the windowed estimation method generating a slow decline in R instead. Death numbers are hugely smoothed compared to infection numbers (due to the long and variable time from infection to death) so I don't think that approach is really viable.
So what I’m trying is a piecewise constant approach, with a chunk length to be determined. I’ll start here with 14 day chunks in which R is held constant, giving us say 12 R values for a 24 week period covering the epidemic (including a bit of a forecast). I choose the starting date to fit the lockdown date into the break between two chunks, giving 4 chunks before and 8 after in this instance.
I’ve got a few choices to make over the prior here, so I’ll show a few different results. The model fit looks ok in all cases so I’m not going to present all of them. This is what we get for the first experiment:

The R values however do depend quite a lot on the details and I’m presenting results from several slightly different approaches in the following 4 plots.
Top right left is the simplest version where each chunk has an independent identically distributed prior for R of N(2,12). This is an example of the MCMC algorithm at the point of failure, in fact a little way past that point as the 12 parameters aren’t really very well identified by the data. The results are noisy and unreliable and it hasn’t converged very well. The last few values of R here should just sample the prior as there is no constraint at all on them. That they do such a poor job of that is an indication of what a dodgy sample it is. However it is notable that there is a huge drop in R at the right time when the lockdown is imposed, and the values before and after are roughly in the right ballpark. Not good enough, but enough to be worth pressing on with….
Next plot on top right is when I impose a smoothness constraint. R can still vary from block to block, but deviations between neighbouring values are penalised. The prior is still N(2,12) for each value, so the last values of R trend up towards this range but don’t get there due to smoothness constraint. The result looks much more plausible to me and the MCMC algorithm is performing better too. However, the smoothness constraint shouldn’t apply across the lockdown as there was a large and deliberate change in policy and behaviour at that point.


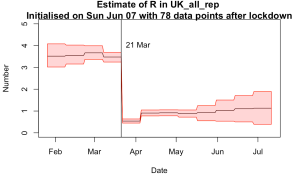

So the bottom left plot has smoothness constraints applied before and after the lockdown but not across it. Note that the pre-lockdown values are more consistent now and the jump at lockdown date is even more pronounced.
Finally, I don’t really think a prior of N(2,12) is suitable at all times. The last plot uses a prior of N(3,12) before the lockdown and N(1,0.52) after it. This is probably a reasonable representation of what I really think and the algorithm is working nicely.
Here is what it generates in terms of daily death numbers:

There is still a bit of of tweaking to be done but I think this is going to be a better approach than the simple 3-chunk version I’ve been using up to now.
5 comments:
> Top right is the simplest version where...
Top left? If only you had a local friendly editor or proof reader :-)
Whichever version, R looks worryingly close to or above 1.
But deaths are falling. So is this R before population immunity applied?
Perhaps you could indicate what the R is in last version both with and without herd immunity effects?
I've been following the evolution of the model sporadically.
Any chance of your putting your R source major online as you make major changes?
You did upload two versions of the model for your preprint article and revision, but since then you:
changed to three R values to take into account changes in shutdown directives.
changed to two-week R value intervals
Changing the published version of the model to make these two changes looks straightforward enough.
But recently you've tweeted:
"I wanted to move towards a more continuously variable R parameter, and the MCMC method had reached its limit with 14-day chunks - about a dozen values - so I dusted off my old trusty iterative EnKF scheme which I haven't used in a decade....and ... it works perfectly!"
Now that's a big change :) And the result looks interesting.
I'm guessing I'm not the only one interested in following major changes as they happen who might be interested in seeing the source to this new version of the model.
We know you already know how to use github :)
Yes absolutely I'll publish the code once I'm happy with a few more details but I'd like to fine-tune a few details first. Currently the code has a huge syntax error but I have an emergency stop before it get there :-)
Chris, it's all the model R, not R_eff, it would be slightly tedious to try to convert but just remember there's a bit more wiggle room than it looks like!
James ...
Great! Looking forward to it. And thanks for the work you're doing.
Post a Comment